接着上篇,本篇主要介绍如何添加限时tryLock方法。介绍完之后,ReentrantLock除了condition之外都会实现,而且基本和实际ReentrantLock代码接近。上篇也提到过,实际ReentrantLock依赖AQS,但是本文不会直接介绍AQS,只是AQS的一个不完全分析。
顺便提一下,“自己写ReentrantLock和ReentrantReadWriteLock”由于篇幅比较长,预计会分成3到4篇左右。
在进入限时tryLock方法的介绍之前,考虑一个问题:上篇中FairLock1和UnfairLock1是否可以复用Node?
为什么要问这个问题?因为C++代码比较关注对象的生命周期。使用C++实现锁的话必须关注何时可以回收Node的内存。如果你了解CLHLock的话,可以知道CLHLock是可以复用Node的,最多是N个(线程)+1个(哨兵)Node,理论上不需要回收。所以和CLHLock基本一致的FairLock1,同样可以用类似CLHLock的方式,即复用前序节点为自己的当前节点(CLHLock是复用前序节点的,至于为什么可以参阅CLHLock的介绍)。UnfairLock1中由于可能是非公平模式,不知道前序节点是谁,也就无法简单复用了。

继续考虑限时获取锁的时候,Node是否可以复用?老实说,个人不知道确切答案,但是即使是在公平模式下,限时tryLock想要复用Node比UnfairLock1也要难很多。比如线程B获取锁超时,但是之后线程C进入了队列,这时线程B再次尝试获取锁的时候会怎么样?首先B由于获取失败,无法复用前序节点。其次C有可能持有B的节点指针,也有可能跳过B链到了B的前序节点上。因此,实现带超时tryLock时一般会考虑每次都新建Node来减少复杂性。
可能因为示例代码是Java,所以每次new一个Node出来没什么感觉。但是假如你用C++实现带超时版本的tryLock的话,必须考虑谁来回收Node的内存。有兴趣的可以看一下相关带超时的锁的论文,比如TOLock。
第二个要考虑的问题是,允许限时会带来什么影响?
- 前序节点有可能已超时
- 后续节点有可能已超时
- (除了哨兵节点)head不可能是超时节点
在上图中,C的前序节点B已超时,为了让A能唤醒自己,C需要设置自己的previous指针到A以及A的next指针为自己。当然signal successor标志也是要设置的。对于A来说,后续节点B已超时,A需要唤醒自己的后续节点中没有超时的第一个节点,即C。第三点不难理解,head的推进是由已经获取锁的线程处理的,所以新的head指针肯定对应一个非超时的线程。
需要继续考虑第一和第二点。当A和C同时执行时,如何设计包括B在内的一个机制,保证C肯定会被唤醒(允许多次唤醒)?
UnfairTimedLock1
以下是基于AQS改造的限时锁,具体分析下如何保证唤醒线程C。
import javax.annotation.Nonnull;
import javax.annotation.Nullable;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.LockSupport;
@SuppressWarnings("Duplicates")
public class UnfairTimedLock1 implements Lock {
private final Queue queue = new Queue();
private final AtomicInteger reentrantTimes = new AtomicInteger(0);
private Thread owner;
public boolean tryLock(long time, @Nonnull TimeUnit unit) throws InterruptedException {
if (owner == Thread.currentThread()) {
// reentrant
reentrantTimes.incrementAndGet();
return true;
}
if (reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
owner = Thread.currentThread();
return true;
}
final long deadline = unit.toNanos(time) + System.nanoTime();
Node node = new Node(Thread.currentThread());
Node predecessor = queue.enqueue(node);
long nanos;
while (true) {
if (predecessor == queue.head.get() &&
reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
myTurn(predecessor, node);
return true;
}
nanos = deadline - System.nanoTime();
// timeout
if (nanos <= 0L) {
abort(predecessor, node);
return false;
}
switch (predecessor.status.get()) {
case Node.STATUS_ABORTED:
predecessor = queue.skipAbortedPredecessors(predecessor, node);
predecessor.successor.set(node);
break;
case Node.STATUS_SIGNAL_SUCCESSOR:
LockSupport.parkNanos(this, nanos);
break;
case Node.STATUS_NORMAL:
/*
* recheck is required after CAS
* 1. CAS failed
* 2. CAS successfully, but status changed to ABORTED before parking
* 3. predecessor unlock between first check and CAS(no unpark)
*/
predecessor.status.compareAndSet(Node.STATUS_NORMAL, Node.STATUS_SIGNAL_SUCCESSOR);
break;
}
if (Thread.interrupted()) {
abort(predecessor, node);
throw new InterruptedException();
}
}
}
private void abort(@Nonnull Node predecessor, @Nonnull Node node) {
node.clearThread();
Node p = queue.skipAbortedPredecessors(predecessor, node);
Node ps = p.successor.get();
// linearization point
node.status.set(Node.STATUS_ABORTED);
/*
* at end
*
* A -> |<B>
* ANY -> |ABORTED
*
* no lost-wakeup problem
*/
if (queue.tail.get() == node && queue.tail.compareAndSet(node, p)) {
/*
* failure is ok, which means
* new node may enqueue between removing and setting successor
*/
p.successor.compareAndSet(ps, null);
return;
}
/*
* at beginning
*
* A -> |<B> -> C
* ANY -> |ABORTED -> ANY
*
* lost-wakeup problem may happen
*
* scenarios
* 1. B didn't set flag of A
*
* 2. B was signaled
* sequence
* a. B set flag
* b. A signaled B
* c. B aborted
*/
if (p == queue.head.get()) {
signalNormalSuccessor(node);
return;
}
/*
* in middle
*
* A -> |B -> <C> -> D
* ANY -> |ANY -> ABORTED -> ANY
*
* lost-wakeup problem may happen
*
* conditions
* 1. no one set flag of B
* 1.1 D set flag of C before C aborts
* 1.2 C didn't set the flag of B
*
* 2. B acquired lock and finished processing after p == head check
*
* first, try to set flag of B, then recheck if predecessor finished(unlocked or aborted)
*/
if (p.ensureSignalSuccessorStatus() && p.thread.get() != null) {
Node s = node.successor.get();
if (s != null && s.status.get() != Node.STATUS_ABORTED) {
p.successor.compareAndSet(ps, s);
}
} else {
signalNormalSuccessor(node);
}
}
private void myTurn(@Nonnull Node predecessor, @Nonnull Node node) {
owner = Thread.currentThread();
node.clearThread();
queue.head.set(node);
node.predecessor.set(null);
predecessor.successor.set(null);
}
private void signalNormalSuccessor(@Nonnull Node node) {
Node successor = queue.findNormalSuccessor(node);
if (successor != null) {
LockSupport.unpark(successor.thread.get());
}
}
public void unlock() {
if (owner != Thread.currentThread()) {
throw new IllegalStateException("not the thread holding lock");
}
int rt = reentrantTimes.get();
if (rt < 1) {
throw new IllegalStateException("reentrant times < 1 when try to unlock");
}
if (rt > 1) {
reentrantTimes.set(rt - 1);
return;
}
// rt == 1
owner = null;
// linearization point
reentrantTimes.set(0);
Node node = queue.head.get();
if (node != null &&
node.status.get() == Node.STATUS_SIGNAL_SUCCESSOR &&
node.status.compareAndSet(Node.STATUS_SIGNAL_SUCCESSOR, Node.STATUS_NORMAL)) {
signalNormalSuccessor(node);
}
}
@Override
public void lock() {
throw new UnsupportedOperationException();
}
@Override
public void lockInterruptibly() throws InterruptedException {
throw new UnsupportedOperationException();
}
@Override
public boolean tryLock() {
throw new UnsupportedOperationException();
}
@Override
@Nonnull
public Condition newCondition() {
throw new UnsupportedOperationException();
}
@SuppressWarnings("Duplicates")
private static class Queue {
final AtomicReference<Node> head = new AtomicReference<>();
final AtomicReference<Node> tail = new AtomicReference<>();
/**
* Enqueue node.
*
* @param node new node
* @return predecessor
*/
@Nonnull
Node enqueue(@Nonnull Node node) {
Node t;
while (true) {
t = tail.get();
if (t == null) {
// lazy initialization
Node sentinel = new Node();
if (head.get() == null && head.compareAndSet(null, sentinel)) {
tail.set(sentinel);
}
} else {
node.predecessor.lazySet(t);
// linearization point
if (tail.compareAndSet(t, node)) {
t.successor.set(node);
return t;
}
}
}
}
@Nullable
Node findNormalSuccessor(@Nonnull Node node) {
Node n = node.successor.get();
if (n != null && n.status.get() != Node.STATUS_ABORTED) {
return n;
}
// find normal node from tail
Node c = tail.get();
n = null;
// tail maybe null during lazy initialization
while (c != null && c != node) {
if (c.status.get() != Node.STATUS_ABORTED) {
n = c;
}
c = c.predecessor.get();
}
return n;
}
@Nonnull
Node skipAbortedPredecessors(@Nonnull Node predecessor, @Nonnull Node node) {
Node h = head.get();
Node p = predecessor;
while (p != h && p.status.get() != Node.STATUS_ABORTED) {
p = p.predecessor.get();
/*
* set predecessor every time to help successors of
* current node to find the normal predecessor more quickly
*/
node.predecessor.set(p);
}
return p;
}
}
/**
* Node.
* <p>
* Status change:
* NORMAL -> ABORTED
*/
private static class Node {
static final int STATUS_NORMAL = 0;
static final int STATUS_ABORTED = -1;
static final int STATUS_SIGNAL_SUCCESSOR = 1;
/**
* thread will be null if
* 1. abort
* 2. enter mutual exclusion area
*/
final AtomicReference<Thread> thread;
final AtomicInteger status = new AtomicInteger(STATUS_NORMAL);
final AtomicReference<Node> predecessor = new AtomicReference<>();
// optimization
final AtomicReference<Node> successor = new AtomicReference<>();
Node() {
this(null);
}
Node(@Nullable Thread thread) {
this.thread = new AtomicReference<>(thread);
}
boolean ensureSignalSuccessorStatus() {
int s = this.status.get();
return s == STATUS_SIGNAL_SUCCESSOR ||
(s == STATUS_NORMAL && this.status.compareAndSet(s, STATUS_SIGNAL_SUCCESSOR));
}
void clearThread() {
thread.set(null);
}
}
}
首先Node增加了status,替换掉了原先的signal successor标志。status的迁移图如下
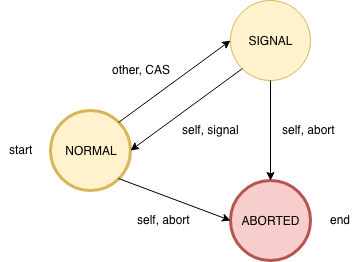
总共有4种迁移。一个线程在创建了Node之后,先是NORMAL。有后续节点挂上了之后,被设置为SIGNAL。如果当前线程超时了的话,变成ABORTED(实际也就是直接设置为ABORTED)。除了后续节点所对应的线程通过CAS修改当前线程拥有的节点之外,其余都是当前线程自身修改。
为什么原先是直接设置的,现在要CAS?看了迁移图后相信很容易理解。为了防止后续节点将ABORTED状态修改为SIGNAL。
在此基础上继续分析保证唤醒的机制。
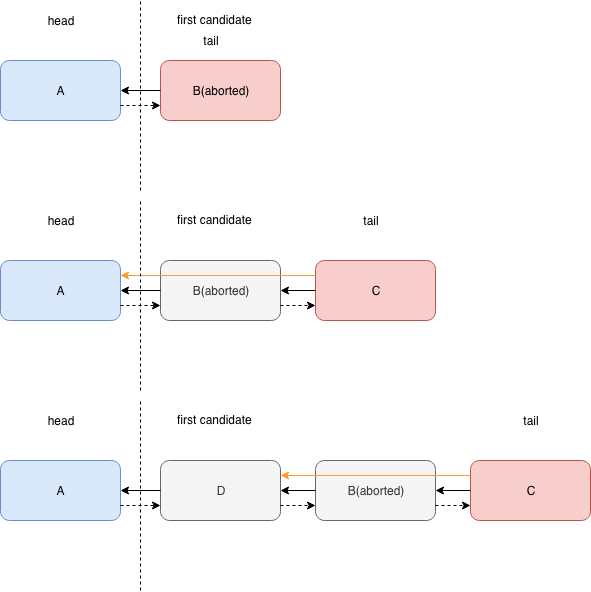
假设线程在设置自己的节点为ABORTED之后,开始解决唤醒问题。
先从最简单的开始,即上图的上部。B没有后续节点,那么肯定没有唤醒问题。这块对应abort方法中node == tail时候的代码。如果CAS tail为前置节点成功的话,说明自己真的是末尾节点,接下来CAS设置前置节点的next指针为空。这里并没有检查CAS的返回值。CAS失败的时候意味着在CAS tail指针之后有新节点入队了。从另一个角度来说,为了防止B的处理覆盖掉新入节点的设置,这里必须用CAS。
接下来分析B为第一个候选节点的情况,即上图的中间部分。要知道B为了让A能够唤醒自己,会设置A的status为SIGNAL。那么B abort时,A的status是SIGNAL还是NORMAL?回答是两者都有可能。tryLock的代码中,在第一次检查nanos是否小于0的时候,有可能超时时间太短,直接被判定为超时的话,A的status为NORMAL。另一种情况是设置A的status为SIGNAL之后,线程被中断。当然还有线程park中被中断,等待超时等情况,此时A的status为SIGNAL。
你可能会问,是否可以一律设置A的状态为SIGNAL,让分析更简单一些?回答是,这样做可能不太好。因为当B明显超时时间过短无法获取锁并放弃了的话,为什么要让A负责唤醒B?虽说多次唤醒比忘记唤醒引起的问题小,但是作为一个同步器还是希望尽量精确唤醒。
继续分析C的情况。
- C在B放弃之后,尝试让B唤醒自己,CAS不成功加上再次读取B的status的时候发现B已经放弃了,此时C会越过B尝试设置A的status,并在A的status被确实设置为SIGNAL之后park
- C在B放弃之前,尝试让B唤醒自己
- 再次读取B的status时为ABORTED,接下来与1一样
- 再次读取B的status时为SIGNAL,即B还没放弃,C会park
也就说B,C同时运行时,C有可能在不知道B放弃的情况下park
另一方面对A来说
- B已放弃
- B未设置A的状态为SIGNAL,A不会唤醒B,唤醒丢失
- B设置了A的状态为SIGNAL,A跳过B,唤醒C
- 虽然B未设置,但是C设置了A的状态为SIGNAL,A在查找后续节点时跳过了B,唤醒C
- B未放弃
- B未设置A的状态为SIGNAL,A不会唤醒B,唤醒丢失
- B设置了A的状态为SIGNAL,A唤醒B,唤醒丢失
额外的,假设A在unlock时,C以公平模式获取锁成功(非公平模式的话不存在C节点)并且推进了head节点(即,C跳过了B以及head变成了C)的话,A的错位唤醒有可能会唤醒C之后的节点。
可以看到,当B是第一个候选节点的时候,C有可能设置不了A的SIGNAL,A也有在好几种可能唤醒不了C。所以AQS的策略是一律让B唤醒C。UnfairTimedLock1中基本也是参考AQS,只是上述分析全部是我自己考虑出来的。
具体代码在abort方法中判断p(predecessor)是否为head,如果是的是,就无论自己的状态一律唤醒。
顺便说一句,在使用spin策略的限时锁中,全权由C来跳过放弃了的B,省去了上述的分析。
最后是B不是第一候选节点并且不在tail的情况,即上图下面的部分。直觉上来说,由于不是第一候选节点,A要唤醒的是D,C也会跳过B链接到D上,不太可能出现唤醒丢失的问题。这里最关键的是确认D的status一定被设置为SIGNAL。那么D的status有可能是NORMAL么?
看了之前中间部分的分析之后,可以说是有可能的,条件如下
- C在B放弃前park了(线程C分析2.2)
- B超时时间过短,直接放弃
此时要求B确保D的status为SIGNAL,所以会有abort中ensureSignalSuccessorStatus这个调用。
继续提问,是否只要设置D的status为SIGNAL就可以了?
答案是:除了设置D的status之外,还要确保D没有unlock。假设ensureSignalSuccessorStatus成功,D可能了发生什么呢?
- D在ensureSignalSuccessorStatus调用之前获取了锁又释放了锁,此时D不会唤醒C,唤醒丢失
- D在ensureSignalSuccessorStatus调用之后释放了锁(获取可以在之前或之后),此时D会唤醒C
- D在ensureSignalSuccessorStatus调用之前放弃,ensureSignalSuccessorStatus会失败,C需要A来唤醒
- D在ensureSignalSuccessorStatus调用之后放弃,由于D是第一候选节点,按照上面中间部分的说明,D会无条件唤醒后续节点,即C
情况1比较麻烦,检查D是否以及完成的条件只能在myTurn方法中找,实际可用的只有一个,thread == null。当然你也可以选择增加status。情况3由于ensureSignalSuccessorStatus会失败,不用增加判断。
以上分析对应abort最后的代码,如果ensureSignalSuccessorStatus成功和thread != null时才可以认为没有唤醒丢失的问题,其余情况即1和3,需要无条件唤醒C。情况3中有可能A唤醒了C,B也唤醒了C,但是考虑到A可能去唤醒D了,所以此处还是需要B确定C被唤醒。
条件中成功时此时B可以选择帮助D设置next指针为C,CAS失败此处没有影响。
abort中最复杂的分析至此结束。实际AQS的代码把图中中间和下部的情况和在一起考虑。
老实说个人觉得abort时的唤醒分析确实比较复杂,从编码上一律唤醒可能是最简单的,但是AQS分析了一部分并且用排除的方式解决了一部分不需要唤醒的情况,理解这块代码可能是设计UnfairTimedLock1最关键的地方。
abort中还有一些代码,比如最开始的设置thread为null。个人理解这是放弃了的线程减少被额外唤醒用的,比如作为第一个候选节点的时候。上面的分析中,基本都是依赖status来判断节点是否放弃,没有看到用thread == null来判断是否abort的地方。当然如果我的分析错了,欢迎指出。
abort中在设置status为ABORTED之前,还有一段跳过放弃了的节点的代码。个人理解在设置status之前是为了防止后续节点跳过自己简化分析。理论上放在设置status之后也是可以的,甚至不跳过也不会造成太大问题。
说到跳过放弃了的节点,Queue#skipAbortedPredecessors中不是找到了第一个未放弃的节点之后设置自己的previous指针,而是遍历时每次都设置。个人理解是想做多线程下的helping,即A在skip时,A后面的节点在skip时,可以通过A更快找到未放弃的节点。只是考虑到skipAbortedPredecessors时(包括abort方法)节点还没设置status为ABORTED,理论上,A的后续节点遍历到了A就停下了。即使A skip之后,立马abort,后续节点也不需要这种helping。所以个人这块持保留意见(如果AQS的cancelAcquire方法原先是在设置status之后skip的话另当别论)。至少在现在的ReentrantLock中应该是不需要的。
UnfairTimedLock2
在写好了限时版tryLock之后,其他lock方法依样画葫芦得到的最终版。
import javax.annotation.Nonnull;
import javax.annotation.Nullable;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.LockSupport;
@SuppressWarnings("Duplicates")
public class UnfairTimedLock2 implements Lock {
private final Queue queue = new Queue();
private final AtomicInteger reentrantTimes = new AtomicInteger(0);
private Thread owner;
public void lock() {
if (tryLock()) {
return;
}
Node node = new Node(Thread.currentThread());
queue.enqueue(node);
while (true) {
if (queue.isNextCandidate(node) &&
reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
myTurn(node);
return;
}
if (isReadyToPark(node)) {
LockSupport.park(this);
}
}
}
public void lockInterruptibly() throws InterruptedException {
if (tryLock()) {
return;
}
Node node = new Node(Thread.currentThread());
queue.enqueue(node);
while (true) {
if (queue.isNextCandidate(node) &&
reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
myTurn(node);
return;
}
if (isReadyToPark(node)) {
LockSupport.park(this);
}
if (Thread.interrupted()) {
abort(node);
throw new InterruptedException();
}
}
}
public boolean tryLock() {
if (owner == Thread.currentThread()) {
// reentrant
reentrantTimes.incrementAndGet();
return true;
}
if (reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
owner = Thread.currentThread();
return true;
}
return false;
}
public boolean tryLock(long time, @Nonnull TimeUnit unit) throws InterruptedException {
if (tryLock()) {
return true;
}
final long deadline = unit.toNanos(time) + System.nanoTime();
Node node = new Node(Thread.currentThread());
queue.enqueue(node);
long nanos;
while (true) {
if (queue.isNextCandidate(node) &&
reentrantTimes.get() == 0 && reentrantTimes.compareAndSet(0, 1)) {
myTurn(node);
return true;
}
nanos = deadline - System.nanoTime();
// timeout
if (nanos <= 0L) {
abort(node);
return false;
}
if (isReadyToPark(node)) {
LockSupport.parkNanos(this, nanos);
}
if (Thread.interrupted()) {
abort(node);
throw new InterruptedException();
}
}
}
private boolean isReadyToPark(@Nonnull Node node) {
Node p = node.predecessor.get();
int s = p.status.get();
if (s == Node.STATUS_SIGNAL_SUCCESSOR) {
return true;
}
if (s == Node.STATUS_ABORTED) {
p = queue.skipAbortedPredecessors(node);
p.successor.set(node);
} else if (s == Node.STATUS_NORMAL) {
p.status.compareAndSet(Node.STATUS_NORMAL, Node.STATUS_SIGNAL_SUCCESSOR);
}
return false;
}
private void abort(@Nonnull Node node) {
node.clearThread();
Node p = queue.skipAbortedPredecessors(node);
Node ps = p.successor.get();
// linearization point
node.status.set(Node.STATUS_ABORTED);
if (queue.tail.get() == node && queue.tail.compareAndSet(node, p)) {
p.successor.compareAndSet(ps, null);
return;
}
if (p != queue.head.get() && p.ensureSignalSuccessorStatus() && p.thread.get() != null) {
Node s = node.successor.get();
if (s != null && s.status.get() != Node.STATUS_ABORTED) {
p.successor.compareAndSet(ps, s);
}
} else {
signalNormalSuccessor(node);
}
}
private void myTurn(@Nonnull Node node) {
owner = Thread.currentThread();
node.clearThread();
queue.head.set(node);
reentrantTimes.set(1);
Node predecessor = node.predecessor.get();
node.predecessor.set(null);
predecessor.successor.set(null);
}
private void signalNormalSuccessor(@Nonnull Node node) {
if (node.status.get() == Node.STATUS_SIGNAL_SUCCESSOR) {
node.status.compareAndSet(Node.STATUS_SIGNAL_SUCCESSOR, Node.STATUS_NORMAL);
}
Node successor = queue.findNormalSuccessor(node);
if (successor != null) {
LockSupport.unpark(successor.thread.get());
}
}
public void unlock() {
if (owner != Thread.currentThread()) {
throw new IllegalStateException("not the thread holding lock");
}
int rt = reentrantTimes.get();
if (rt < 1) {
throw new IllegalStateException("reentrant times < 1 when try to unlock");
}
if (rt > 1) {
reentrantTimes.set(rt - 1);
return;
}
// rt == 1
owner = null;
// linearization point
reentrantTimes.set(0);
Node node = queue.head.get();
if (node != null && node.status.get() == Node.STATUS_SIGNAL_SUCCESSOR) {
signalNormalSuccessor(node);
}
}
@Override
@Nonnull
public Condition newCondition() {
throw new UnsupportedOperationException();
}
@SuppressWarnings("Duplicates")
private static class Queue {
final AtomicReference<Node> head = new AtomicReference<>();
final AtomicReference<Node> tail = new AtomicReference<>();
/**
* Enqueue node.
*
* @param node new node
* @return predecessor
*/
@Nonnull
Node enqueue(@Nonnull Node node) {
Node t;
while (true) {
t = tail.get();
if (t == null) {
// lazy initialization
Node sentinel = new Node();
if (head.get() == null && head.compareAndSet(null, sentinel)) {
tail.set(sentinel);
}
} else {
node.predecessor.lazySet(t);
// linearization point
if (tail.compareAndSet(t, node)) {
t.successor.set(node);
return t;
}
}
}
}
@Nullable
Node findNormalSuccessor(@Nonnull Node node) {
Node n = node.successor.get();
if (n != null && n.status.get() != Node.STATUS_ABORTED) {
return n;
}
// find normal node from tail
Node c = tail.get();
n = null;
// tail maybe null during lazy initialization
while (c != null && c != node) {
if (c.status.get() != Node.STATUS_ABORTED) {
n = c;
}
c = c.predecessor.get();
}
return n;
}
boolean isNextCandidate(@Nonnull Node node) {
return node.predecessor.get() == head.get();
}
@Nonnull
Node skipAbortedPredecessors(@Nonnull Node node) {
Node h = head.get();
Node p = node.predecessor.get();
while (p != h && p.status.get() != Node.STATUS_ABORTED) {
p = p.predecessor.get();
/*
* set predecessor every time to help successors of
* current node to find the normal predecessor more quickly
*/
node.predecessor.set(p);
}
return p;
}
}
/**
* Node.
* <p>
* Status change:
* NORMAL -> ABORTED
*/
private static class Node {
static final int STATUS_NORMAL = 0;
static final int STATUS_ABORTED = -1;
static final int STATUS_SIGNAL_SUCCESSOR = 1;
/**
* thread will be null if
* 1. abort
* 2. enter mutual exclusion area
*/
final AtomicReference<Thread> thread;
final AtomicInteger status = new AtomicInteger(STATUS_NORMAL);
final AtomicReference<Node> predecessor = new AtomicReference<>();
// optimization
final AtomicReference<Node> successor = new AtomicReference<>();
Node() {
this(null);
}
Node(@Nullable Thread thread) {
this.thread = new AtomicReference<>(thread);
}
boolean ensureSignalSuccessorStatus() {
int s = this.status.get();
return s == STATUS_SIGNAL_SUCCESSOR ||
(s == STATUS_NORMAL && this.status.compareAndSet(s, STATUS_SIGNAL_SUCCESSOR));
}
void clearThread() {
thread.set(null);
}
}
}
如果你看过AQS的源代码的话,你可能会注意这里的tryLock和AQS的tryAcquire,isReadyToPark和shouldParkAfterFailedAcquire,abort和cancelAcquire比较接近。有兴趣的话可以对比一下。
小结
限时锁个人认为是比较难实现的一种锁,但是在解决死锁问题等地方会有用。如果你理解了限时锁的分析的话,相信你也能写出类似ReentrantLock一样的锁。
如果你想更全面地了解锁的实现的话,建议阅读《the art of multiprocessor programming》中关于锁的部分。虽然大部分都是spin lock,具体实际基于park代码比较远,但是对训练多线程代码分析和设计很有帮助。
接下来,个人要实现的是ReadWriteLock,具体在第三篇中讲解。
One response to “Java并发研究 自己写ReentrantLock和ReentrantReadWriteLock(2)”
感谢分享!已推荐到《开发者头条》:https://toutiao.io/posts/rdwbpb 欢迎点赞支持!
使用开发者头条 App 搜索 385148 即可订阅《并发与分布式系统研究》