具体上次撰写博客有一段时间了。这段时间内自己学些了很多,想了很多,尝试去理解了很多。结果之一是不管这个博客是为了什么而建立的,我还是把自己的技术思考记录下来。
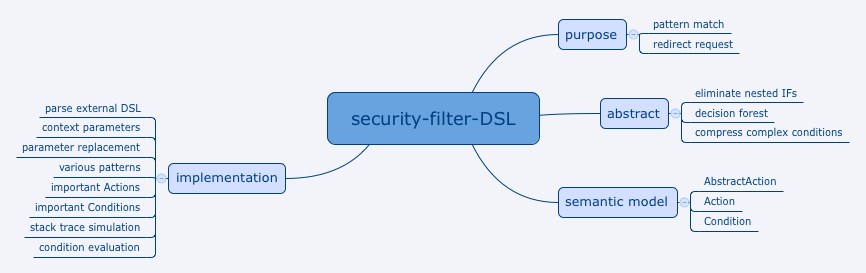
本文描述是自己在工作中实现的一种DSL。DSL是个人今天年初左右才决定的发展方向,只是在具体工作中使用还是第一次。希望这可以作为自己在技术上选择性发展的一个好的开端。
由于是工作中开发出来的一种DSL,所以不会讲太具体的业务场景,而是以技术设计与实现为主。
本DSL的设计目的的核心如题,模式匹配和请求跳转。结合起来就是按照某种业务规则以模式匹配的方式决定请求是否跳转。更直接的一种表达方式是if else决定是否要redirect,只是这段if else是用DSL定义的。
使用DSL定义规则的好处在于更清晰地展现跳转的条件,避免技术实现给业务规则辨识带来的”噪音”,特别是复杂的跳转规则。其次是快速支持规则的变化,比如易变(不管是运行时易变,还是需求期易变)的规则,附带的另外一个好处是如果业务上需要动态定义的话,DSL可以快速支持,不再需要通过数据库设计,配置等传统方式。
设计思路
本DSL设计目的如上文所讲是if else决定是否需要redirect。具体业务场景是通过多个变量的判断来决定的,而且这些多个判断会形成多层嵌套if。虽然可以通过提前返回(return),拆分方法,约定前置条件等手段消除多层嵌套,但是会带来规则难以辨识等副作用。DSL的引入是为了通过类似“决策森林”的方式分离多层嵌套if。换句话说,用类似goto的方式跳转。模型上是从A决策树的叶子节点链接到另外一个决策树B的根节点上。为什么整体不是一个大的决策树呢?原因是部分决策树的叶子节点会导向到同一个决策节点,这时决策树就退化为“决策图”一样的东西了。另外一般人对多层嵌套(对应height值比较大的决策树)理解比较难,比如首先判断胎压是否正常,然后判断发动机是否正常,再判断刹车正常然后可以正常启动这样的规则,但是对高度为1的决策树比如判断车况正常然后可以正常启动很容易理解。所以本DSL里全是高度为1的决策树,即使是复杂的条件也会被整合到单个变量,并且由这些“单层if”组成了最终的规则。
第二点是判断方式的选择。简单变量的判断自然不用多说,用类Java中的switch case方式即可实现。但是复杂条件的单变量方式并不能直接判断,这里用约定方式来判断。比如USER_STATUS,用户状态,如果不存在用户的话这个值该是什么呢?为null?假如用户状态本来就是null呢?这里实际上就是一个二次判断,但是组合到单变量的话,约定用户不存在的话用NONE表示,其他状态原样判断,只要用户状态没有NONE这个值就没有问题。细心的人会发现编程上可以用
Option(user).map(_.getStatus) match {
case None => // do stuff
case Some(STATUS_A) => // do stuff
case _ => // the other status
}
这样的方式来完成单变量的判断的(上面的语言为Scala)。这里是DSL,所以没有严格按照上面这种方式,而是借用了一下NONE这种类名作为约定。
语义模型
设计DSL首先设计语义模型。既不是设计你的DSL语法,也不是BNF,而是你的语义模型。这里的语义模型与设计目的关系比较大。因为本次设计目的不算复杂,所以很快导出了语义模型(请允许用Scala描述,Java背景的人相信也不会太难理解这块表示,因为接近UML表示)
sealed abstract class AbstractAction {
def execute(context: ActionExecutionContext): AbstractAction
}
abstract class Condition extends AbstractAction
abstract class Action extends AbstractAction {
def execute(context: ActionExecutionContext) = {
doExecute(context)
null
}
def doExecute(context: ActionExecutionContext): Unit
}
Action和Condition是两大核心概念。一个是执行动作,一个条件判断。作为两者的抽象AbstractAction要求执行时返回一个AbstractAction。定义返回null为停止,即Action。定义有返回值的为Condition。原则上不允许Action返回其他AbstractAction。
Action和Condition输入ExecutionContext,执行上下文,具体的动作执行和变量获取都是委托给这个ExecutionContext执行的。
给一个简单例子来表明一个简单的if如何映射到这个模型上
if(user.type == admin) print("admin")
else print("other")
这里的user.type即为Condition,print为Action,转化为DSL
MATCH USER_TYPE CASE admin => CALL PRINT admin DEFAULT CALL PRINT OTHER
具体的外部DSL语法由解析器支持,如果你愿意的话,直接编程方式组装这段也是可行的。
典型DSL
最简单的脚本
LABEL ROOT CALL PASS
不用太担心,语义模型中没有定义具体的Action和Condition,所以实际的Action完全可以你自己定义,现在这里的语法、动作和条件都是现有框架下的东西,你可以在基本的语义模型基础上设计更多更复杂的Action和Condition,这完全决定于你。
由于解析器与执行的约定,每个决策树需要一个名字,用于ReferenceContext的定义,语法为LABLE 决策树名。默认从ROOT决策树开始执行。
示例不同Pattern的用法
SET SOME_URI = /foo.shtml LABEL ROOT MATCH REQUEST_URI CASE /foo.htm => CALL DEBUG foo CASE ^/foo\.html$ => CALL DEBUG foo2 CASE `SOME_URI` => CALL DEBUG foo3 DEFAULT CALL DEBUG other
示例决策树跳转
LABEL ROOT MATCH REQUEST_URI CASE /foo.htm => GOTO FOO CASE /bar.htm => GOTO BAR DEFAULT GOTO OTHER LABEL FOO MATCH REQUEST_METHOD CASE GET => CALL DEBUG FOO_GET CASE POST => CALL DEBUG_FOO_POST DEFAULT CALL DEBUG FOO_POST
你可以从这个多决策树的例子开始,一般的可执行DSL就是一个多个决策树的决策森林。
实现细节
外部DSL解析实现
理论上用内部DSL也是可以的,但是如果你看到之后的一个动态规则刷新(RefreshableActionReferenceContext),你就会觉得外部DSL还是不错的。
解析器的设计规则是简单。话句话说,我不会引入任何需要JavaCC等语法解析器才可以处理的语法,按照空格,按照逗号分割已经足够了。
为了构建决策森林,一种简单的方法是用层次化的结构表示,比如XML的嵌套。不过考虑到决策树会被复用,比如A决策树和B决策树的计算结果可能都是C决策树,这样就会退化到类似Spring的bean定义,没有多层嵌套的形式。那样的话,个人觉得给每个决策树定义一个名字(这里为LABEL),提供引用(这里为GOTO)就可以了。LABEL的语法为
忽略#开始的行。你可以用#作为注释行的起始。
忽略空行。
LABEL ROOT
定义一个叫做ROOT的决策树。
单行,LABEL开始,空格,ROOT为决策树的名字。重复定义会导致前面定义的被覆盖。
GOTO OTHER
跳转到叫做OTHER的决策树。
GOTO一般不用来单独定义,接在Condition的分支中,比如之间那些MATCH的CASE和DEFAULT子句。
CALL PASS
调用PassAction
CALL开始表示调用某个Action,之后跟着Action的名字和相关参数。
MATCH REQUEST_METHOD CASE GET => CALL PASS CASE POST => GOTO METHOD_POST DEFAULT GOTO OTHER
这里构造了一个Condition,每个Condition必须以MATCH开始,每个CASE就是Condition的主要判断条件,DEFAULT指示在所有条件都不满足时该如何处理。
可以看到CASE的 => 右边以CALL开始的肯定是Action,GOTO开始的肯定是跳转到另外一个决策树。DEFAULT之后也是类似的语法。
一些特殊的用法
LABEL ROOT CALL PASS
LABEL虽然是定义一个决策树,但也可以直接接动作。
从以上的语法来看,解析不是很难,基本都是单行命令,除了CASE起始的行,所以实际上解析器就是先判断起始关键字LABEL CALL MATCH CASE DEFAULT等然后决定如何构造模型,不是非常复杂。
上下文变量与变量替换
上下文变量不是语义模型中定义的,而是为了实际运行时能够替换模式匹配的变量而设计出来的功能。具体使用场景比如你有这么一段DSL
MATCH REQUEST_URI CASE A => CALL AAA CASE B => CALL BBB DEFAULT CALL OTHER
语义模型中其实没有定义这里的REQUEST_URI来源,也就是说你可以认为是“预定义变量”,也可以认为是之前或者之后某个地方定义的变量。为了方便调试,这里选择了“预定义变量”+“前定义变量”的方式。实际实现中,由于“前定义变量”是之后加上的,所以部分变量没有实现。其次是部分变量比较复杂,在DSL中复杂条件时的变量的话会引入更大的复杂性,实际也没有实现。总之,上下文变量在这里肯定有”预定义变量“,是否有”前定义变量“需要看具体情况。以下是有前定义变量的一段DSL:
SET REQUEST_METHOD PUT MATCH REQUEST_METHOD CASE GET => CALL PASS CASE POST => CALL PASS DEFAULT CALL SHOW_ERROR UNEXPECTED_REQUEST_METHOD
执行这段DSL时,如果你用POST方式请求,因为”前定义变量(PUT)“比”预定义变量(POST)“高,所以会执行到DEFAULT分支,即显示UNEXPECTED_REQUEST_METHOD。如果你把SET那行删除的话,那么执行分支会落到CASE POST上去。
四个上下文
虽然是很简单的语义模型,但是实现时会遇到各种细节问题。在不断设计与实现中,从一个执行上下文最终定型了三个上下文:执行上下文(ExecutionContext),引用上下文(ReferenceContext)和解析上下文(ParserContext)。
ExecutionContext
这是在语义模型中定义的上下文,Action和Condition调用这个上下文执行动作或者获取测试变量值。
ReferenceContext
在实现DSL解析时遇到了一个问题,如果用户先设定跳转到某个决策树,但是这个决策树尚未定义,换句话说,A方法调用B方法,但是B方法是在A方法之后才定义的,这时用显示的节点关联就存在问题了。简单的解决方式是给一个虚拟的节点关联,在实际执行时查找这个决策树的根,这样同时也可以放开DSL的定义方式,不需要强制以自底向上的方式定义了,更加自由。为了实现这种虚拟的节点关联,引入了NamedAction和ReferenceContext,前者保存了跳转的目标决策树的名字,后者保存了所有决策树的根节点的引用。如果你问为什么不直接用ExecutionContext来实现这种功能,我只能说虽然引用像是执行的一部分,但引用上下文在解析时就已经决定了,而且执行上下文在实际执行时才创建,所以你应该单独创建这个上下文。当然,你可能看到实际的执行上下文中有引用上下文,那主要是因为上下文变量也被定义到引用上下文中去了,执行时为了获取这些变量必须依赖引用上下文,还有从引用上下文中获取ROOT决策树的引用。
ParserContext
解析上下文,仅在解析时有用的上下文。主要作为解析时的临时变量存储的地方,从设计模式来说更类似于Builder的角色,解析完毕之后不在有用。
RefreshableActionReferenceContext
可刷新的引用上下文,这是一个非常强大的功能,你可以修改运行中的规则。这对于动辄10分钟部署的Java复杂应用的开发来说虽然有限但是也很有用。具体来说就是,每隔指定时间读取文件,判断是否和之前保存的文件哈希值相同,避免解析没有任何变化的规则。如果规则有变化,重新解析规则并替换现有规则。
多种Pattern
Pattern Match是一种很强大的功能,但是在DSL中你可能没法那么自由地定义复杂的Pattern。开发到现在为止,确定的Pattern主要有三种,用于三类不同场景或者变量。三种Pattern的语法如下:
CASE AAA CASE ^/foo\.htm$ CASE `SOME_VAR`
第一种是最简单的,即字面量。判断时只需要直接比较字面量和变量值即可。
第二种是正则表达式,主要用于URI的判断,要求必须以^开始,以$结束。整体作为一个正则表达式尝试匹配变量。
第三种是变量值展开,学过Scala的就知道这个`不是单引号,是back-tick,SOME_VAR是之前定义的变量,即上面讲的上下文变量中,更具体点说是用SET命令定义的变量。比较时会查找这个变量的值与测试的变量进行比较。
我觉得有些人会问假如我需要 变量值展开+正则表达式 呢?很遗憾现在是不支持的。但是考虑到现在判断REQUEST_URI其实用字面量也可以,不像URL那种后面会带很多参数,所以建议你使用 字面量+变量值展开的方式,即常规的变量值展开的写法。在进一步提升解析器的功能之前,个人暂时不考虑再加复杂的Pattern。
不过事情没那么糟糕,因为每个”预定义变量“的条件是单独实现的,如果你愿意,可以在条件判断时自行分析Pattern并与测试值比较来满足你的特别的需求。事实上,REQUEST_URI_END就是一个典型的例子,它的内部实现会尝试展开变量值并用 PatternValue.endsWith(TestValue) 的方式执行,这并不是一种典型的比较变量值相等的方式,所以必须单独实现。
判断实现
在了解了Pattern之后,理解整个Pattern Match就不会那么难了。一开始因为只有字面量这种Pattern,所以直接用HashMap查找的方式来实现的。在确定了三种Pattern之后,只能顺序判断了。另外如果定义了多个一模一样的CASE的话,现在执行和解析都不会报错。理论上解析时需要在遇到冗余CASE就报”编译错误“,之后如果有时间我会考虑加上去。
重要的Action
DebugAction
测试时候使用的Action,只是调用ActionExecutionContext#debug(String),输入参数用来标示来自哪里。
PassAction
最简单的Action,什么都不做。通常作为正常情况收尾的Action。比如最简单的DSL,什么都不做,让请求直接通过。
LABEL ROOT CALL PASS
ShowAction
显示指定页面。如果指定页面与当前页面一致,什么都不做,否则跳转到指定的页面。(如果你不判断,会死循环)对于security-filter来说,跳转通常意味着权限不够,重定向到登陆页让你重新登陆(如果你没登陆的话),或者显示一段信息提示你权限不够,或者你可以把跳转作为流程控制的一种手段,在有多步的时候,在DSL中定义跳转到第几步,这其实就是这段DSL的开发初衷。
ShowAction除了输入跳转目标之外,还有两个参数
allowPost 允许POST请求。现在想想,这可能不是一个必要的选项。这个选项的效果是你对一个POST请求设置了allowPost之后,跳转逻辑会被忽略,请求肯定会落到指定页面的后台逻辑上。
parameters 额外的参数。默认情况下,请求进来的参数会自动带到跳转的目标地址上,比如你请求进来是http://exmaple.com/foo.htm?a=b&c=d,跳转目标是http://example.com/bar.htm, 那么最终跳转的URL会变成http://example.com/bar.com?a=b&c=d。如果你设置了额外参数,那么额外参数会追加到这个URL后。
ShowErrorAction
显示错误页面。这是一个特定的Action,接受一个错误页面地址和一个异常码。不支持ShowAction的那两个额外参数。如果当前地址不是错误页面地址的话(必须判断,否则会死循环),跳转并显示指定的异常码。 当然你也可以自己修改这个Action,执行一些额外的逻辑。这一切都是允许的,因为Action的逻辑不在语义模型的范畴中,只需要满足Action的要求即可。
重要的Condition
RequestUriCondition, RequestMethodCondition
很明显,就是RequestUri和RequestMethod的条件。执行标准的判断逻辑(等于),支持全部三种Pattern。
RequestUriEndCondition
一个自定义的条件,判断方式就如之前所说的,PatternValue.endsWith(TestValue)。接受back-tick形式的Pattern和字面量Pattern,不支持正则表达式Pattern。如果你需要自定义Condition实现,可以看看这个类。
其他其实还有好多业务相关的Condition,但是在整理为框架时我删掉了。如果你要把这个DSL应用到你的项目中,你只需要增加你自己的Condition或者Action就行了。
异常的堆栈模拟
为了在DSL执行过程中定位预期的和非预期的异常,个人为DSL设计了一个类似Java的Stack Trace一样的堆栈,在堆栈中你可以看到执行的步骤和上下文变量。这个DSL虽然是以决策树构建起来的,但是存在跳转,从一棵决策树的叶子跳到另一个决策树的根,所以抽象上来说,存在执行步骤,具体来说就是经过了哪些决策树。上下文变量被加进来用于更好地理解执行步骤,这里的上下文变量不仅包括DSL中用SET命令定义的变量,还包括执行上下文中的运行时变量(如果有的话)。
实际的堆栈日志如下
raise error, code SOME_ERROR_CODE_2, execution description ATTRIBUTES: {X=1} RUNTIME_VARIABLES: {matchValue=1} ACTION STACK: [ShowErrorAction [errorLocationCode=errorLink, errorCode=SOME_ERROR_CODE_2], NamedAction[STEP2], RequestUriCondition[branches=[(RegexPattern [^/bar.htm$], NamedAction[STEP2])],fallback=DebugAction [value=N1]]]
你可以通过这段Execution Description了解执行的步骤来定位失败的原因。
总结
此文前前后后写了好长时间,开发花了很长时间,介绍也写了很长时间。语义模型虽然很简单,但是实现很复杂。这也是我第一次应用DSL设计的思路的案例,可能没有那些分布式、大数据量的那么宏大那么复杂,但是也算是在一个小问题上的深度挖掘,遇到类似问题的人可以随意裁剪并适配到你的项目中,也希望给予其他人在DSL设计上的一点参考。